
오늘은 Google Colab에서 파이썬을 사용하여 선형 회귀 분석을 쉽게 따라 할 수 있도록 단계별로 설명하겠습니다. 이번 글에서는 기본적인 선형 회귀 모델을 만들고, 학습시키고, 평가하는 과정을 다루는데, 구글 코랩에서 기본적으로 주어지는 sample_data를 통한 데이터를 기반으로 주택의 중간 가격을 예측하는 방법을 배워 보겠습니다.
1. Google Colab 준비하기
Google Colab은 파이썬 코드 실행에 최적화된 환경으로, 무료로 사용할 수 있는 강력한 도구입니다. Colab에 접속한 후 새 노트북을 만들어 코드를 작성하고 실행할 수 있습니다. 구글 코랩에 대한 내용은 아래 링크에서 확인 가능합니다.


2. 데이터 로드하기
먼저, 사용할 데이터를 로드합니다. Colab에서는 준비된 샘플 데이터를 쉽게 사용할 수 있습니다. 여기서는 california_housing_test.csv 파일을 사용해 보겠습니다.
import pandas as pd
# 데이터 로드
data = pd.read_csv('/content/sample_data/california_housing_test.csv')
# 데이터 확인
data.head()#결과
longitude latitude housing_median_age total_rooms total_bedrooms \
0 -122.05 37.37 27.0 3885.0 661.0
1 -118.30 34.26 43.0 1510.0 310.0
2 -117.81 33.78 27.0 3589.0 507.0
3 -118.36 33.82 28.0 67.0 15.0
4 -119.67 36.33 19.0 1241.0 244.0
population households median_income median_house_value
0 1537.0 606.0 6.6085 344700.0
1 809.0 277.0 3.5990 176500.0
2 1484.0 495.0 5.7934 270500.0
3 49.0 11.0 6.1359 330000.0
4 850.0 237.0 2.9375 81700.0 위 코드에서는 pandas 라이브러리를 사용하여 CSV 파일을 불러옵니다. data.head()를 통해 데이터의 첫 5개 행을 확인하여, 데이터가 어떻게 구성되어 있는지 파악할 수 있습니다.
3. 데이터 전처리하기
모델을 학습시키기 전에 데이터를 전처리해야 합니다. 여기서는 특성(입력 변수)과 타겟(예측하고자 하는 변수)을 분리한 후, 데이터를 학습용과 테스트용으로 나눕니다.
# 특성과 타겟 분리 - 1
X = data.drop('median_house_value', axis=1) # 입력 변수들
y = data['median_house_value'] # 타겟 변수
# 학습 및 테스트 데이터 분리 - 2
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 데이터 정규화 - 3
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)X에는 예측에 사용할 입력 변수들이,y에는 예측하고자 하는 중간 주택 가격이 저장됩니다.train_test_split을 통해 데이터를 학습용과 테스트용으로 나눕니다.- 보통 80%는 학습에, 20%는 테스트에 사용합니다.
StandardScaler를 사용해 데이터를 정규화하여 학습이 더 잘 이루어지도록 합니다.
4. 선형 회귀 모델 구축 및 학습
이제 Scikit-learn의 LinearRegression 클래스를 사용하여 선형 회귀 모델을 만들고, 학습시켜 보겠습니다.
from sklearn.linear_model import LinearRegression
# 모델 생성 및 학습 - 1
model = LinearRegression()
model.fit(X_train, y_train)
# 테스트 데이터로 예측 - 2
y_pred = model.predict(X_test)LinearRegression()을 통해 선형 회귀 모델을 생성합니다.fit메소드를 사용하여 학습 데이터를 기반으로 모델을 학습시킵니다.- 학습된 모델로 테스트 데이터를 예측합니다.
5. 모델 성능 평가하기
모델이 얼마나 정확하게 예측하는지 평가해야 합니다. 여기서는 평균 제곱 오차(MSE)를 사용하여 성능을 평가합니다.
from sklearn.metrics import mean_squared_error
# 모델 평가 - 1
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')#결과
Mean Squared Error: 4586505886.68125mean_squared_error함수를 사용하여 MSE를 계산합니다.
MSE 값이 낮을수록 모델의 예측이 실제 값과 가까움을 의미합니다.
6. 결과 시각화하기
마지막으로, 예측 결과와 실제 값을 시각적으로 비교해 보겠습니다. 시각화를 통해 모델의 예측이 얼마나 정확한지 직관적으로 확인할 수 있습니다.
import matplotlib.pyplot as plt
# 예측 결과 vs 실제 값 시각화 - 1
plt.scatter(y_test, y_pred)
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
plt.title('Actual vs Predicted')
plt.show()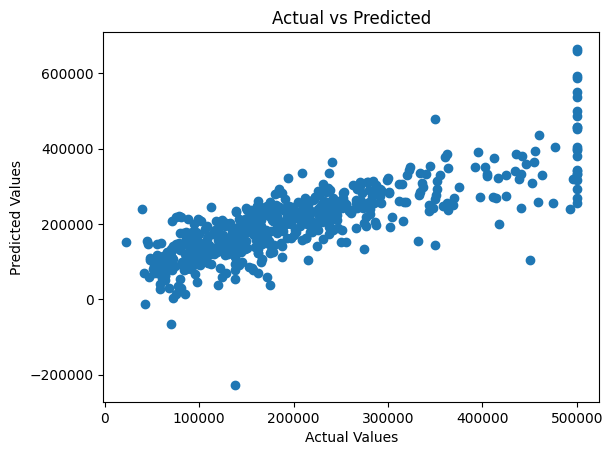
matplotlib라이브러리를 사용하여 예측 값과 실제 값을 비교하는 그래프를 그립니다.
그래프에서 점들이 45도 선에 가까울수록 예측이 정확하다는 것을 알 수 있습니다.
7. 전체 코드
아래는 위에서 설명한 모든 과정을 포함한 전체 코드입니다.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
# 데이터 로드
data = pd.read_csv('/content/sample_data/california_housing_test.csv')
# 특성과 타겟 분리
X = data.drop('median_house_value', axis=1)
y = data['median_house_value']
# 학습 및 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 데이터 정규화
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 모델 생성 및 학습
model = LinearRegression()
model.fit(X_train, y_train)
# 테스트 데이터로 예측
y_pred = model.predict(X_test)
# 모델 평가
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
# 예측 결과 vs 실제 값 시각화
plt.scatter(y_test, y_pred)
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
plt.title('Actual vs Predicted')
plt.show()8. 결론
이번 글에서는 Google Colab을 활용하여 파이썬으로 선형 회귀 분석을 수행하는 과정을 단계별로 살펴보았습니다. 데이터를 로드하고 전처리하는 방법부터, 선형 회귀 모델을 구축하고 학습시키며, 그 결과를 평가하고 시각화하는 과정까지 다루었습니다.
선형 회귀 분석은 머신러닝의 기초이자 다양한 데이터 분석 작업에 활용할 수 있는 중요한 기법입니다. 특히 이번 예제에서는 주택의 중간 가격을 예측하기 위해 모델을 사용하였으며, 이를 통해 실제 값과 예측 값의 차이를 줄이는 것이 모델 성능 개선의 핵심이라는 점을 확인할 수 있었습니다.
이번 글에서는 Google Colab 에서 주어진 sample_data로 머신러닝 중 하나인 선형회귀의 실습을 해보았습니다. 다음 포스팅에선 다른 머신러닝의 실습을 해보겠습니다.
최신글
![[Python] 배열 나누기(Split) - Numpy Tutorial 6](https://develog.co.kr/wp-content/uploads/2024/09/Numpy-150x150.png)