
안녕하세요, 오늘은 Python을 배우고 머신러닝, 딥러닝을 실습할 수 있는 두 가지 방법에 대해 이야기해 보려고 합니다. 우리가 사용할 수 있는 방법은 Python을 컴퓨터에 설치하는 방법과 Google Colab을 이용하는 방법입니다. 이 두 가지 방법을 함께 살펴보면서 각각의 이점과 한계를 알아보겠습니다!
Python을 컴퓨터에 설치하고 실행하기
첫 번째 방법은 우리 컴퓨터에 직접 Python을 설치하여 실행하는 것입니다. 이 방법을 사용할 때 가장 많이 활용되는 도구는 Anaconda와 비주얼 스튜디오 코드(Visual Studio Code)입니다.
Anaconda와 비주얼 스튜디오 코드란?
- Anaconda: 데이터 과학과 머신러닝 분야에서 매우 널리 사용되는 Python 배포판입니다. 다양한 패키지를 손쉽게 관리하고 설치할 수 있어, 처음 프로그래밍을 배우는 사람들에게 아주 유용합니다. 특히, Jupyter Notebook과 함께 사용하면 더욱 직관적으로 작업할 수 있습니다.
- 비주얼 스튜디오 코드: Microsoft가 개발한 강력한 코드 편집기로, Python 코드 작성 시 매우 유용합니다. 다양한 확장을 통해 필요한 기능을 쉽게 추가할 수 있어 많은 개발자들이 선호합니다.
장점
- 성능: 고성능의 컴퓨터를 가지고 있다면, 더 빠르고 복잡한 딥러닝 알고리즘을 실행하는 데 큰 도움이 됩니다.
- GPU 활용: 고성능 GPU를 사용할 수 있어 학습 속도가 빨라지고, 대규모 모델을 다룰 때 유리합니다.
- 오프라인 작업: 인터넷 연결 없이도 작업할 수 있는 점이 큰 장점입니다.
단점
- 비용: 고성능 장비를 구매하는 데 높은 비용이 들 수 있으며, GPU를 활용하기 위해서는 추가적인 전기료와 냉각 장치가 필요할 수 있습니다.
- 설치와 환경 설정: 다양한 Python 패키지를 설치하고 환경을 설정하는 과정이 다소 복잡할 수 있습니다.

Google Colab을 이용하기
두 번째 방법은 Google Colab을 사용하는 것입니다. Google Colab은 구글이 제공하는 웹 기반의 Python 코드 실행 환경으로, 인터넷만 있으면 저사양의 컴퓨터로도 딥러닝 코드를 작성하고 테스트할 수 있습니다.
Google Colab의 특징
- 클라우드 환경: 어떤 장치에서든 접근 가능하여 이동이 매우 편리합니다. 또한, 다른 사람들과 코드 공유도 쉽게 할 수 있습니다.
- 패키지 기본 설치: TensorFlow, PyTorch, NumPy 등 다양한 딥러닝 관련 패키지가 기본적으로 설치되어 있어, 따로 설치할 필요가 없습니다.
- GPU 사용 가능: 무료로 GPU를 제공받아 성능 좋은 계산을 할 수 있어, 딥러닝 실습에 매우 유리합니다.
- Jupyter Notebook 형식: Jupyter Notebook과 유사한 형식으로 작업하므로, 실시간으로 결과를 확인하며 학습할 수 있습니다.
추가 기능
- 코드 실행 시간 관리: Colab에서는 런타임을 관리할 수 있어 연속적으로 코드를 실행하거나 체크포인트를 설정할 수 있습니다.
- Google Drive 연동: Google Drive와 쉽게 연동하여 데이터 저장 및 불러오기 과정이 간편합니다.
단점
- 실시간 어플리케이션: 실시간으로 작동하는 앱을 만들기는 어려운 점이 있습니다. 예를 들어, 게임 같은 것은 Colab에서 구현하기 힘들죠.
- 사용 시간 제한: 무료 계정에서는 런타임이 일정 시간 동안만 유지되며, 다시 연결할 때 작업 내용이 초기화될 수 있습니다.
- 인터넷 필요: 모든 작업이 인터넷을 통해 이루어지므로 안정적인 네트워크 환경이 필요합니다.
Python 및 머신러닝 시작하기
이제 Google Colab이나 Anaconda와 같은 환경에서 Python 및 머신러닝을 어떻게 시작할 수 있는지 간단히 알아보겠습니다.
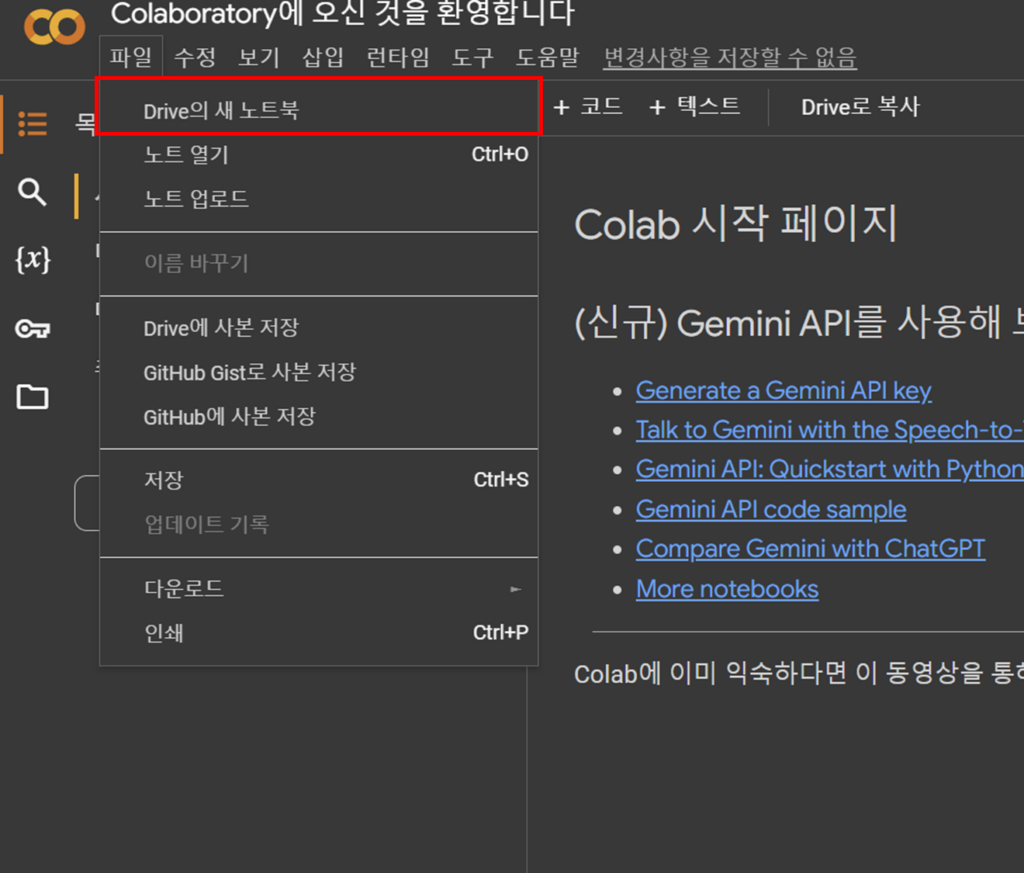
Google Colab 시작하기
- Google Colab에 접속합니다.
- 새로운 노트북을 만들고, Python 코드를 입력하고 실행합니다.

예를 들어, 다음의 간단한 코드를 입력해 보겠습니다:
python
print("Hello, Google Colab!")
>>Hello, Google Colab! // 간단한 print문 이었습니다.데이터 로딩 및 전처리
데이터 로딩
이제 간단한 머신러닝을 실습해보겠습니다. 머신러닝 프로젝트의 첫 번째 단계는 데이터를 로드하는 것입니다. 데이터는 Google Drive, Kaggle, UCI Machine Learning Repository와 같은 다양한 출처에서 다운로드할 수 있습니다. 예를 들어, Kaggle에서는 데이터셋을 다운로드하고 로컬 시스템에 저장한 후, 이를 Python에서 읽어들일 수 있습니다.
python
import pandas as pd
# 데이터 파일 로드
data = pd.read_csv('path/to/your/dataset.csv')
Google Drive에서 데이터를 로드하는 방법은 Google Colab을 사용하는 경우 다음과 같습니다:
python
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
data = pd.read_csv('/content/drive/MyDrive/path/to/your/dataset.csv')
데이터 전처리
데이터를 로드한 후에는 전처리 과정이 필요합니다. 이 과정에는 결측값 처리, 데이터 정규화, 특성 선택, 데이터 분할 등이 포함됩니다.
python
# 결측값 처리
data = data.dropna() # 결측값이 있는 행 삭제
# 데이터 정규화
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data[['feature1', 'feature2']])
# 데이터 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(scaled_data, data['target'], test_size=0.2, random_state=42)
모델 구축
TensorFlow를 이용한 모델 구축
TensorFlow와 Keras를 사용하여 간단한 인공신경망 모델을 구축할 수 있습니다. 다음은 기본적인 신경망 모델의 예시입니다:
python
import tensorflow as tf
from tensorflow.keras import layers, models
# 모델 정의
model = models.Sequential()
model.add(layers.Dense(128, activation='relu', input_shape=(784,))) # 입력층
model.add(layers.Dense(10, activation='softmax')) # 출력층
# 모델 컴파일
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
여기서 input_shape은 입력 데이터의 차원을 나타냅니다. 출력층의 활성화 함수로 softmax를 사용하여 클래스 확률을 예측합니다.
모델 학습 및 평가
모델을 학습시키고 평가하는 과정은 다음과 같습니다:
python
# 모델 학습
history = model.fit(X_train, y_train, epochs=10, validation_split=0.2)
# 모델 평가
test_loss, test_acc = model.evaluate(X_test, y_test)
print(f'Test accuracy: {test_acc}')
이 코드에서 epochs는 학습의 반복 횟수를 나타내며, validation_split은 훈련 데이터의 일부를 검증 데이터로 사용하는 비율을 지정합니다. evaluate 함수는 테스트 데이터에서 모델의 성능을 평가합니다.
결과 시각화
Matplotlib을 이용한 시각화
모델 학습 과정의 결과를 시각화하면 성능을 보다 명확하게 이해할 수 있습니다. 예를 들어, 학습 과정에서의 정확도를 시각화할 수 있습니다:
python
import matplotlib.pyplot as plt
# 학습 과정에서의 정확도 시각화
plt.plot(history.history['accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.show()
여기서 history.history['accuracy']는 학습 과정 동안의 정확도를 담고 있으며, plt.plot을 통해 이를 그래프로 나타낼 수 있습니다.
Seaborn을 이용한 시각화
Seaborn을 사용하여 보다 세련된 시각화를 제공할 수도 있습니다. 예를 들어, 학습 및 검증 정확도를 함께 시각화할 수 있습니다:
python
import seaborn as sns
history_df = pd.DataFrame(history.history)
sns.lineplot(data=history_df[['accuracy', 'val_accuracy']])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.show()
Seaborn은 데이터프레임을 직접 시각화할 수 있어, 다양한 스타일과 옵션을 제공하여 시각화를 더욱 효과적으로 할 수 있습니다.
결론
이제 두 가지 방법에 대해 알아보았습니다. 컴퓨터에 직접 Python을 설치하는 방법은 성능이 뛰어나지만, 설치와 환경 설정이 복잡하고 비용이 많이 드는 반면, Google Colab은 비용 없이 쉽게 사용할 수 있지만 실시간 애플리케이션 개발에는 한계가 있습니다.
각자의 상황에 맞게, 두 방법 중 적절한 것을 선택하면 됩니다. 다음 블로그에서는 Python과 머신러닝, 딥러닝의 기초에 대해 더 깊이 알아보도록 하겠습니다.
참고 자료
최신글
![[프로그래머스] 잘라서 배열로 저장하기 - 자바](https://develog.co.kr/wp-content/uploads/2025/01/프로그래머스-잘라서-배열로-저장하기-자바-150x150.png)
![[프로그래머스] 붕대 감기 - 자바](https://develog.co.kr/wp-content/uploads/2024/11/프로그래머스-붕대-감기-자바-150x150.png)
![[프로그래머스] 달리기 경주 - 자바](https://develog.co.kr/wp-content/uploads/2024/11/프로그래머스-달리기-경주-자바-150x150.png)
![[프로그래머스] 추억 점수 - 자바](https://develog.co.kr/wp-content/uploads/2024/11/JAVA-추억-점수-프로그래머스-150x150.png)
