
이번 시간에는 통계학에서 표와 그림을 통한 자료의 요약에 대해 알아보고 구글 코랩에서 파이썬으로 데이터 시각화 실습까지 해보겠습니다. 먼저 자료가 주어질 때 우리는 주어진 자료로 전체적인 경향을 분석하거나 새로운 사실에 대해 유추가 가능합니다. 하지만 하나하나 보기에는 시간도 오래 걸리고 지루한 과정일 뿐입니다. 만약 오랜 시간을 거쳐 분석을 끝냈을 때 원하지 않는 분석 결과가 나온다면 시간만 버린다고 볼 수 있습니다. 그래서 보통은 자료의 개요에 대해 쉽게 파악하기 위해서 표와 그림을 통해 파악하는데요, 자료의 형태에 따라 구분하는 방식이 달라지므로 자료 형태의 종류부터 알아보고 분석하는 법도 알아보겠습니다.
0. 구글 코랩으로 시작하기
이번 포스팅은 구글 코랩에서 진행됩니다.


1. 데이터의 형태
통계학에서 자료는 일반적으로 수치형 자료(numercial data)와 범주형 자료(categorical data)로 구분됩니다. 수치형 자료는 양적 자료라고도 불리는데 두 가지 종류가 있습니다.
수치형 자료(양적 자료)
- 연속형 자료(continuous data): 연속적인 값(키, 몸무게와 같이 관측 가능한 값)
- 이산형 자료(discrete data): 셀 수 있는 값(교통사고 건수)
범주형 자료도 질적 자료로 불리며 두 가지 종류가 있습니다.
범주형 자료(질적 자료)
- 순위형 자료(ordinal data): 범주 간에 순서의 의미가 존재하는 값
- 명목형 자료(nominal data): 범주 간에 순서의 의미가 존재하지 않는 값
수집된 자료는 관심의 대상이 되는 특성을 측정 또는 관측한 결과로서, 그와 같이 관측되는 특성을 변수(variable)라고 합니다. 위 자료형들은 각각의 변수를 가지고 있습니다. 따라서 자료의 형태는 아래와 같이 정리될 수 있습니다.
- 수치형 변수: 관측 결과가 수치로 나타나는 변수
- 연속형 변수: 연속적인 값을 갖는 변수
- 이산형 변수: 셀 수 있는 값을 갖는 변수
- 범주형 변수: 관측 결과가 범주의 형태로 나타나는 변수
- 순위형 변수: 순서의 의미가 있는 범주
- 명목형 변수: 순서의 의미가 없는 범주
수치형 자료가 범주형 자료로 변환되는 경우도 있는데요, 예를 보겠습니다.
- EX1)시험 성적 자료에서 100~90점, 90~80점, 80~70점, 70~60점, 60점 미만의 점수를 각각 A, B ,C ,D F의 평점으로 표현하면 시험점수라는 수치형 자료를 평점이라는 범주형 자료로 변환됨.
- EX2) 어느 지점을 통과하는 자동차의 수를 기록한 후에 자동차의 수가 10,000대 미만은 ‘적다’, 10,000대 이상 100,000대 미만은 ‘보통’, 100,000대 이상은 ‘많다’로 변환됨. 이때 전에는 ‘이산형 자료’, 후에는 ‘순위형 자료’로 볼 수 있음.
2. 범주형 데이터의 요약
범주형 데이터는 보통 각 값들보다 값들의 퍼센테이지를 중심으로 보게 됩니다. 자료들의 요약형태는 도수 분포표(Frequency Table), 원형그래프(Pie Chart), 막대그래프(Bar Chart), 파레토그림(Pareto Diagram) 등이 있는데요, 각 요약 형태로 범주형 자료의 요약을 해보겠습니다.
2.1 도수분포표(Frequency Table)
먼저 도수분포표에서 사용하는 단어들을 살펴보겠습니다.
- 도수: 각 범주에 속하는 관측값의 개수
- 상대도수: 도수를 자료의 전체 개수로 나눈 비율
- 도수분포표: 범주형 자료에서 범주와 그 범주에 대응하는 도수와 상대도수를 나열하여 작성한 표
예제를 보겠습니다.
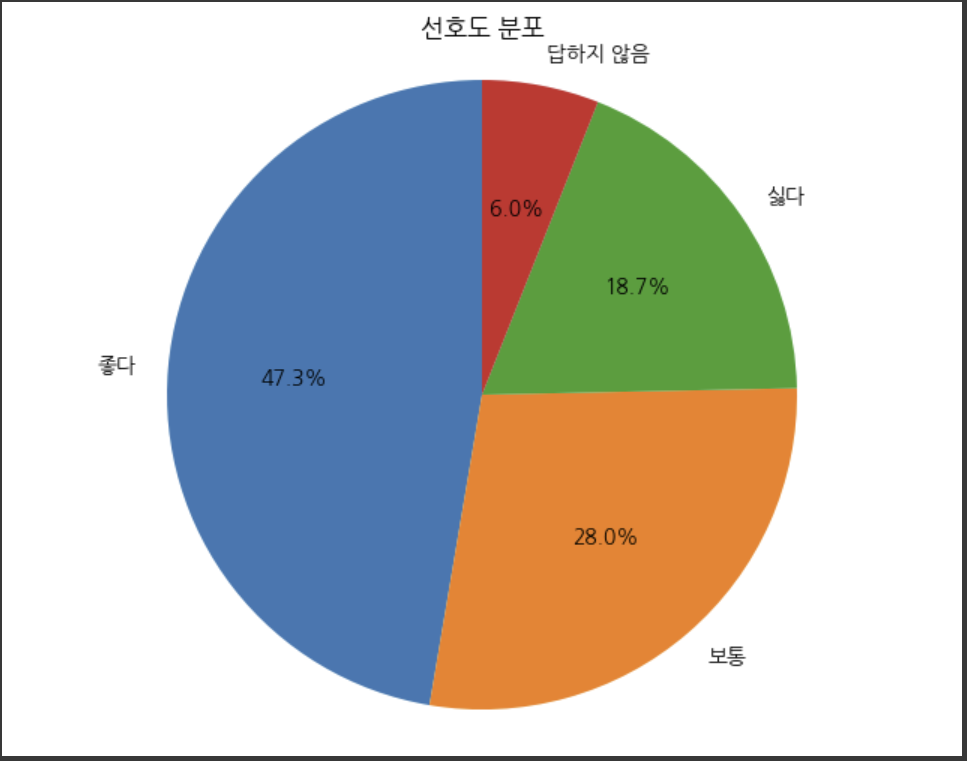
- EX1)한 회사에서 새로 개발한 자동차의 외형에 대하여 고객 150명을 임의로 뽑아 선호도를 조사하였다. 150명 중에서 71명은 좋다고 답하고, 42명은 보통으로 답하고, 28명은 싫다고 답하고, 9명은 답을 하지 않았다. 조사에 대한 도수분포도를 작성하라.
먼저 일반적인 결과 입니다.
| 답 | 도수 | 상대도수 |
|---|---|---|
| 좋다 | 71 | 0.473 |
| 보통 | 42 | 0.280 |
| 싫다 | 28 | 0.187 |
| 무응답 | 9 | 0.060 |
| 합 | 150 | 1.000 |
위 표를 colab으로 간단하게 만들어보겠습니다.
2.1.1 Import pandas
import pandas as pd먼저 정적인 데이터를 쉽게 관리하기 위한 pandas를 import 해줍니다.
2.1.2 데이터 설정(데이터 전처리)
data = {
'선호도': ['좋다', '보통', '싫다', '답하지 않음'],
'도수': [71, 42, 28, 9]
}사용할 데이터를 ‘선호도’와 ‘도수’로 나누어 리스트 형태로 설정하였습니다.
2.1.3 결과값 구하기
df = pd.DataFrame(data)
total_responses = sum(df['도수'])
df['상대도수'] = df['도수'] / total_responses
total_row = pd.DataFrame({'선호도': ['합'], '도수': [total_responses], '상대도수': [1.0]})
df = pd.concat([df, total_row], ignore_index=True)
print(df)2.1.4 전체 코드
import pandas as pd
data = {
'선호도': ['좋다', '보통', '싫다', '답하지 않음'],
'도수': [71, 42, 28, 9]
}
df = pd.DataFrame(data)
total_responses = sum(df['도수'])
df['상대도수'] = df['도수'] / total_responses
total_row = pd.DataFrame({'선호도': ['합'], '도수': [total_responses], '상대도수': [1.0]})
df = pd.concat([df, total_row], ignore_index=True)
print(df)앞서 Import한 pandas로 데이터 프레임을 생성해주었고, 상대도수를 구하기 위해 전체 응답 수를 구하고 상대도수를 구하는 과정을 순서대로 진행하였습니다. 합계도 추가해줬습니다.
2.1.4 결과
선호도 도수 상대도수
0 좋다 71 0.473333
1 보통 42 0.280000
2 싫다 28 0.186667
3 답하지 않음 9 0.060000
4 합 150 1.000000결과입니다.
이렇게 수치로 정렬하여 표로 나타내는 것도 좋지만 그림을 통하여 살펴보면 개요가 더 쉽게 눈에 들어옵니다. 이러한 이유로 원형 그래프와 막대 그래프 등이 자주 사용됩니다.
2.2 원형그래프(Pie Chart)
원형그래프는 원에서 상대도수에 비례하여 중심각을 나누어 보여주는 요약형태입니다.
2.2.1 예제 1
먼저 위 예시에서 이어 원형그래프를 그려보겠습니다.
원형그래프로 나타내는데에 필요한 코드는 그렇게 많지 않습니다.
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 6))
plt.pie(df['도수'][:-1], labels=df['선호도'][:-1], autopct='%1.1f%%', startangle=90)
plt.title('선호도 분포')
plt.axis('equal') # 원형 그래프를 원으로 표시
plt.show()먼저 시각화 하기 위해 matplotlib를 임포트 해줍니다.
후에 figsize로 전체 그래프의 크기를 설정해주고, pie는 원형그래프를 그리는 코드인데 내부 인수는 아래와 같습니다.
df['도수'][:-1]: 도수 데이터에서 마지막 행(합계)을 제외하고 사용.labels=df['선호도'][:-1]: 선호도 레이블도 마지막 행을 제외하고 사용하여 각 조각에 레이블을 붙임.autopct='%1.1f%%': 각 조각의 비율을 소수점 한 자리까지 표시.startangle=90: 그래프의 시작 각도를 90도로 설정하여 원형 그래프가 위쪽에서 시작.
title 함수로 그래프의 제목을 설정해주고, axis로 equal로 설정해주어 그래프의 비율이 같도록 설정합니다.
마지막으로 show함수를 통해 시각화 합니다.
전체 코드는 아래와 같습니다.
import pandas as pd
import matplotlib.pyplot as plt
data = {
'선호도': ['좋다', '보통', '싫다', '답하지 않음'],
'도수': [71, 42, 28, 9]
}
df = pd.DataFrame(data)
total_responses = sum(df['도수'])
df['상대도수'] = df['도수'] / total_responses
total_row = pd.DataFrame({'선호도': ['합계'], '도수': [total_responses], '상대도수': [1.0]})
df = pd.concat([df, total_row], ignore_index=True)
print(df)
plt.figure(figsize=(8, 6))
plt.pie(df['도수'][:-1], labels=df['선호도'][:-1], autopct='%1.1f%%', startangle=90)
plt.title('선호도 분포')
plt.axis('equal') # 원형 그래프를 원으로 표시
plt.show()colab에서 실행한 결과입니다.
2.2.2 예제 2
새로운 예제를 들어 원형그래프를 하나 더 만들어 보겠습니다.
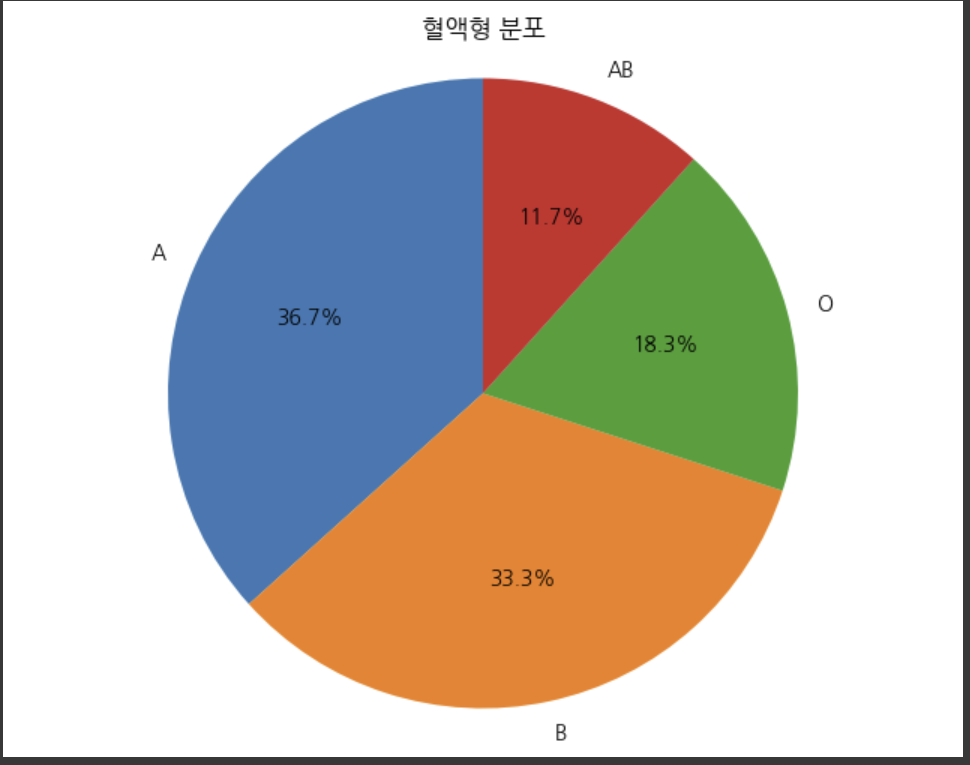
- 어느 고등학교에서 한 학급을 임의로 선택하여 그 학급 60명에 대한 혈액형 검사를 실시한 결과가 다음과 같다. 이 자료에 대한 원형그래프를 그려라.
데이터셋
data = [
['A', 'B', 'B', 'A', 'A', 'O', 'A', 'AB', 'O', 'O', 'A', 'B', 'O', 'AB', 'B'],
['B', 'A', 'O', 'B', 'A', 'B', 'B', 'O', 'AB', 'B', 'A', 'AB', 'A', 'B', 'A'],
['O', 'A', 'A', 'B', 'AB', 'A', 'O', 'B', 'A', 'B', 'B', 'A', 'B', 'A', 'B'],
['AB', 'B', 'A', 'O', 'AB', 'O', 'B', 'A', 'B', 'A', 'O', 'B', 'A', 'A', 'A']
]이전과 같이 하나하나 코드를 살펴보겠습니다.
import matplotlib.pyplot as plt
import pandas as pd먼저 필요한 라이브러리들을 임포트 해줍니다.
data = [
['A', 'B', 'B', 'A', 'A', 'O', 'A', 'AB', 'O', 'O', 'A', 'B', 'O', 'AB', 'B'],
['B', 'A', 'O', 'B', 'A', 'B', 'B', 'O', 'AB', 'B', 'A', 'AB', 'A', 'B', 'A'],
['O', 'A', 'A', 'B', 'AB', 'A', 'O', 'B', 'A', 'B', 'B', 'A', 'B', 'A', 'B'],
['AB', 'B', 'A', 'O', 'AB', 'O', 'B', 'A', 'B', 'A', 'O', 'B', 'A', 'A', 'A']
]
['O', 'A', 'A', 'B', 'AB', 'A', 'O', 'B', 'A', 'B', 'B', 'A', 'B', 'A', 'B'],
['AB', 'B', 'A', 'O', 'AB', 'O', 'B', 'A', 'B', 'A', 'O', 'B', 'A', 'A', 'A']
]
flattened_data = [blood_type for sublist in data for blood_type in sublist]
df = pd.Series(flattened_data)저는 처음에 데이터셋을 설정할 때 2차원 배열로 했기 때문에 다시 1차원 배열로 변환 해줍니다. 전과 같이 pandas 라이브러리의 Series함수를 통해 다루기 쉽게 데이터프레임으로 변환해줍니다.
blood_counts = df.value_counts()
plt.figure(figsize=(8, 6))
plt.pie(blood_counts, labels=blood_counts.index, autopct='%1.1f%%', startangle=90)
plt.title('혈액형 분포')
plt.axis('equal') # 원형 그래프를 원으로 표시
plt.show()마지막으로 혈액형별 개수를 구해주고, 그래프를 그려줍니다.
위와 마찬가지로 figure로 그래프의 크기 설정. pie로 원형그래프에 필요한 인수들을 적어주고 title로 제목 설정, axis로 비율을 맞춰줍니다. 만약 상대도수를 구하고 싶다면 “len(df)”로 총 개수를 구해주고 “blood_counts / 총개수”로 구할 수 있습니다.
전체코드를 아래와 같습니다.
import matplotlib.pyplot as plt
import pandas as pd
data = [
['A', 'B', 'B', 'A', 'A', 'O', 'A', 'AB', 'O', 'O', 'A', 'B', 'O', 'AB', 'B'],
['B', 'A', 'O', 'B', 'A', 'B', 'B', 'O', 'AB', 'B', 'A', 'AB', 'A', 'B', 'A'],
['O', 'A', 'A', 'B', 'AB', 'A', 'O', 'B', 'A', 'B', 'B', 'A', 'B', 'A', 'B'],
['AB', 'B', 'A', 'O', 'AB', 'O', 'B', 'A', 'B', 'A', 'O', 'B', 'A', 'A', 'A']
]
flattened_data = [blood_type for sublist in data for blood_type in sublist]
df = pd.Series(flattened_data)
blood_counts = df.value_counts()
plt.figure(figsize=(8, 6))
plt.pie(blood_counts, labels=blood_counts.index, autopct='%1.1f%%', startangle=90)
plt.title('혈액형 분포')
plt.axis('equal') # 원형 그래프를 원으로 표시
plt.show()결과는 아래와 같습니다.
2.3 막대그래프(Bar Chart)
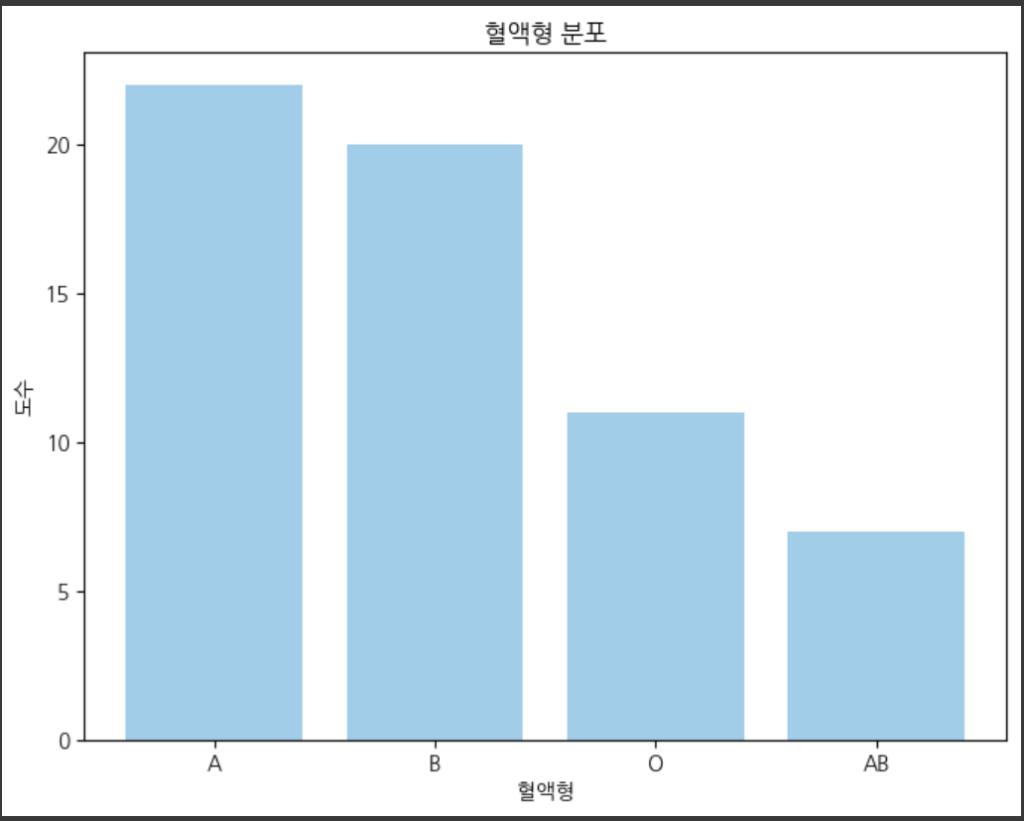
막대그래프는 각 범주에서 도수의 크기를 막대로 표현합니다. 그래프의 한 축에는 도수에 대한 눈금을 그리고, 다른 축에는 범주를 나열합니다. 만약 도수의 크기보다 상대도수를 보고 싶다면 도수 대신 상대도수를 사용하기도 합니다. 위에서 언급한 2번 예시로 막대그래프를 그려보겠습니다.
전체 코드입니다.
import matplotlib.pyplot as plt
import pandas as pd
data = [
['A', 'B', 'B', 'A', 'A', 'O', 'A', 'AB', 'O', 'O', 'A', 'B', 'O', 'AB', 'B'],
['B', 'A', 'O', 'B', 'A', 'B', 'B', 'O', 'AB', 'B', 'A', 'AB', 'A', 'B', 'A'],
['O', 'A', 'A', 'B', 'AB', 'A', 'O', 'B', 'A', 'B', 'B', 'A', 'B', 'A', 'B'],
['AB', 'B', 'A', 'O', 'AB', 'O', 'B', 'A', 'B', 'A', 'O', 'B', 'A', 'A', 'A']
]
flattened_data = [blood_type for sublist in data for blood_type in sublist]
df = pd.Series(flattened_data)
blood_counts = df.value_counts()
plt.figure(figsize=(8, 6))
plt.bar(blood_counts.index, blood_counts.values, color='skyblue')
plt.xlabel('혈액형')
plt.ylabel('도수')
plt.title('혈액형 분포')
plt.show()
결과입니다.
2.4 파레토그림(Pareto Diagram)
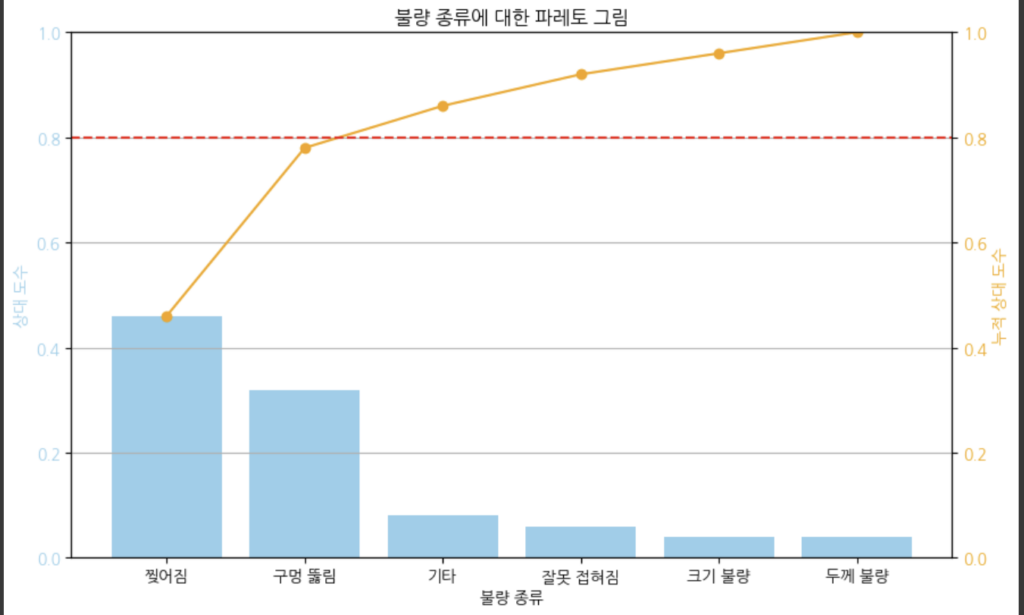
파레토그림은 명목형 자료에서 다수를 점유하고 있는 중요한 소수의 범주를 찾는 요약형태입니다. 이게 무슨 말이냐면 예를 들어 자동차의 고장 원인이 10가지가 존재한다고 가정합니다. 그런데 이 중에서 고장의 원인 중 80%가 자동차의 두 가지 부품이라면 이 두 가지가 “중요한 소수” 라고 할 수 있습니다.
파레토그림은 막대그래프의 일종으로 상대도수의 크기가 큰 순서로 범주를 왼쪽부터 오른쪽으로 배열하여 만듭니다. 가장 큰 막대가 왼쪽, 가장 작은 막대가 오른쪽으로 옵니다. 또한 크기 순서대로 배열된 범주에서 누적상대도수를 구하여 누적도수를 각 범주의 막대 위에 중앙에 표시하고 그 점들을 연결합니다. 이렇게 함으로써 상대도수가 증가하는 정도와 큰 도수의 범주들이 차지하는 비율을 쉽게 파악할 수 있습니다. 파레토그림에서 범주의 순서는 도수의 크기에 따라 변화하므로 순위형 자료와 같이 범주의 순서가 의미 있는 자료는 사용되지 않습니다.
예제를 보겠습니다.
- 어느 화장지 회사에서 생산된 미용용 화장지 500장을 임의로 뽑아 불량품을 조사하여 불량의 종류를 알아보았더니, 구멍 뚫림이 16개, 잘못 접혀짐이 3개, 찢어짐이 23개, 크기 불량이 2개, 두께 불량이 2개, 그리고 4종류의 불량이 각각 1개씩 있었다. 불량품이 1개인 불량의 종류를 기타의 항목으로 묶어 하나의 범주로 하여 불량의 종류에 대한 파레토그림을 그려라.
2.4.1 불량 데이터 분석을 위한 파레토 차트 그리기
먼저, 데이터 분석을 위한 pandas와 시각화를 위한 matplotlib.pyplot 라이브러리를 불러옵니다.
import pandas as pd
import matplotlib.pyplot as plt예제에서 제공해준 데이터로 설정합니다.
data = {
'불량 종류': ['구멍 뚫림', '잘못 접혀짐', '찢어짐', '크기 불량', '두께 불량', '기타'],
'도수': [16, 3, 23, 2, 2, 4] # 기타는 4개로 설정
}여기서 ‘도수’는 각 불량 종류의 발생 빈도를 나타냅니다.
위의 데이터를 기반으로 pandas의 데이터프레임을 생성합니다.
df = pd.DataFrame(data)‘기타’ 항목의 도수를 합산하고, 데이터프레임에서 제거한 뒤, 이를 다시 추가합니다. 이렇게 하면 ‘기타’ 항목이 별도로 존재하지 않고, 다른 불량 종류와 함께 비교할 수 있게 됩니다.
other_count = df[df['불량 종류'] == '기타']['도수'].sum()
df = df[df['불량 종류'] != '기타']
other_df = pd.DataFrame({'불량 종류': ['기타'], '도수': [other_count]})
df = pd.concat([df, other_df], ignore_index=True)불량 종류를 도수에 따라 내림차순으로 정렬합니다. 이를 통해 가장 빈번한 불량 종류부터 쉽게 확인할 수 있습니다.
df = df.sort_values(by='도수', ascending=False)각 불량 종류의 누적 도수를 계산하고, 이를 기반으로 누적 백분율을 구합니다. 누적 백분율은 전체에서 각 항목이 차지하는 비율을 나타내므로, 문제 해결의 우선 순위를 정하는 데 유용합니다.
total_count = df['도수'].sum()
df['상대 도수'] = df['도수'] / total_count
df['누적 도수'] = df['도수'].cumsum()
df['누적 상대 도수'] = df['누적 도수'] / total_count 마지막으로, 파레토 차트를 그립니다. 막대 그래프로 각 불량 종류의 도수를 나타내고, 선 그래프로 누적 백분율을 시각화합니다.
fig, ax1 = plt.subplots(figsize=(10, 6))
ax1.bar(df['불량 종류'], df['상대 도수'], color='skyblue')
ax1.set_xlabel('불량 종류')
ax1.set_ylabel('상대 도수', color='skyblue')
ax1.set_ylim(0, 1) # Y축 범위 설정
ax1.tick_params(axis='y', labelcolor='skyblue')
ax2 = ax1.twinx()
ax2.plot(df['불량 종류'], df['누적 상대 도수'], color='orange', marker='o', linestyle='-')
ax2.set_ylabel('누적 상대 도수', color='orange')
ax2.set_ylim(0, 1) # Y축 범위 설정
ax2.tick_params(axis='y', labelcolor='orange')
plt.title('불량 종류에 대한 파레토 그림')
plt.axhline(0.8, color='red', linestyle='--')
plt.grid(axis='y')
plt.show()전체 코드는 아래와 같습니다.
import pandas as pd
import matplotlib.pyplot as plt
data = {
'불량 종류': ['구멍 뚫림', '잘못 접혀짐', '찢어짐', '크기 불량', '두께 불량', '기타'],
'도수': [16, 3, 23, 2, 2, 4] # 기타는 4개로 설정
}
df = pd.DataFrame(data)
other_count = df[df['불량 종류'] == '기타']['도수'].sum()
df = df[df['불량 종류'] != '기타'] # 기타 항목 삭제
other_df = pd.DataFrame({'불량 종류': ['기타'], '도수': [other_count]})
df = pd.concat([df, other_df], ignore_index=True)
df = df.sort_values(by='도수', ascending=False)
total_count = df['도수'].sum()
df['상대 도수'] = df['도수'] / total_count # 상대 도수 (0~1로 계산)
df['누적 도수'] = df['도수'].cumsum()
df['누적 상대 도수'] = df['누적 도수'] / total_count # 누적 상대 도수 (0~1로 계산)
fig, ax1 = plt.subplots(figsize=(10, 6))
ax1.bar(df['불량 종류'], df['상대 도수'], color='skyblue')
ax1.set_xlabel('불량 종류')
ax1.set_ylabel('상대 도수', color='skyblue')
ax1.set_ylim(0, 1) # Y축 범위 설정
ax1.tick_params(axis='y', labelcolor='skyblue')
ax2 = ax1.twinx()
ax2.plot(df['불량 종류'], df['누적 상대 도수'], color='orange', marker='o', linestyle='-')
ax2.set_ylabel('누적 상대 도수', color='orange')
ax2.set_ylim(0, 1) # Y축 범위 설정
ax2.tick_params(axis='y', labelcolor='orange')
plt.title('불량 종류에 대한 파레토 그림')
plt.axhline(0.8, color='red', linestyle='--') # 80% 기준선
plt.grid(axis='y')
plt.show()결과는 아래와 같습니다.
3. 이산형 자료의 요약
관측된 수치형 자료가 셀 수 있는 경우 그 자료를 이산형 자료라고 합니다. 이때 관측값의 종류가 적으면 범주형 자료로 요약, 많으면 연속형 자료로 요약하게 됩니다. 이때 주의할 점은 이산형 자료는 수치형 자료로서 관측값의 크기가 의미가 있으므로 파레토그림과 같이 범주의 순서가 바뀌는 기법은 피해야 합니다. 위에서 배운 것들을 통해 하나의 이산형 자료 예제를 가지고 도수분포표, 원형그래프, 막대그래프를 colab에서 그려보겠습니다. 이번엔 설명없이 코드와 결과만 첨부하겠습니다.
- EX1) 어느 콩밭에서 60개의 콩깍지를 임의로 추출하여 각 깍지에서의 콩의 개수를 세어 다음과 같이 기록하였다. 다음의 자료를 이용하여 요약하라.
data = [
[4, 3, 4, 3, 3, 5, 5, 6, 4, 4, 4, 3],
[3, 4, 3, 3, 6, 4, 5, 3, 6, 3, 2, 1],
[4, 4, 4, 4, 4, 5, 3, 4, 3, 1, 2, 2],
[5, 2, 4, 3, 5, 5, 3, 3, 3, 3, 5, 5],
[3, 3, 6, 4, 3, 5, 6, 4, 4, 3, 3, 4]
]코드
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 데이터 정의
data = [
[4, 3, 4, 3, 3, 5, 5, 6, 4, 4, 4, 3],
[3, 4, 3, 3, 6, 4, 5, 3, 6, 3, 2, 1],
[4, 4, 4, 4, 4, 5, 3, 4, 3, 1, 2, 2],
[5, 2, 4, 3, 5, 5, 3, 3, 3, 3, 5, 5],
[3, 3, 6, 4, 3, 5, 6, 4, 4, 3, 3, 4]
]
# 데이터 1차원화
flattened_data = [item for sublist in data for item in sublist]
# 도수분포표 생성
frequency_table = pd.Series(flattened_data).value_counts().sort_index()
print("도수분포표:")
print(frequency_table)
# 원형그래프 그리기
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.pie(frequency_table, labels=frequency_table.index, autopct='%1.1f%%', startangle=90)
plt.title('원형그래프')
# 막대그래프 그리기
plt.subplot(1, 2, 2)
frequency_table.plot(kind='bar')
plt.title('막대그래프')
plt.xlabel('콩의 개수')
plt.ylabel('빈도수')
# X축 레이블 수평으로 설정
plt.xticks(rotation=0)
plt.tight_layout()
plt.show()결과
#도수분포표 결과
도수분포표:
1 2
2 4
3 21
4 18
5 10
6 5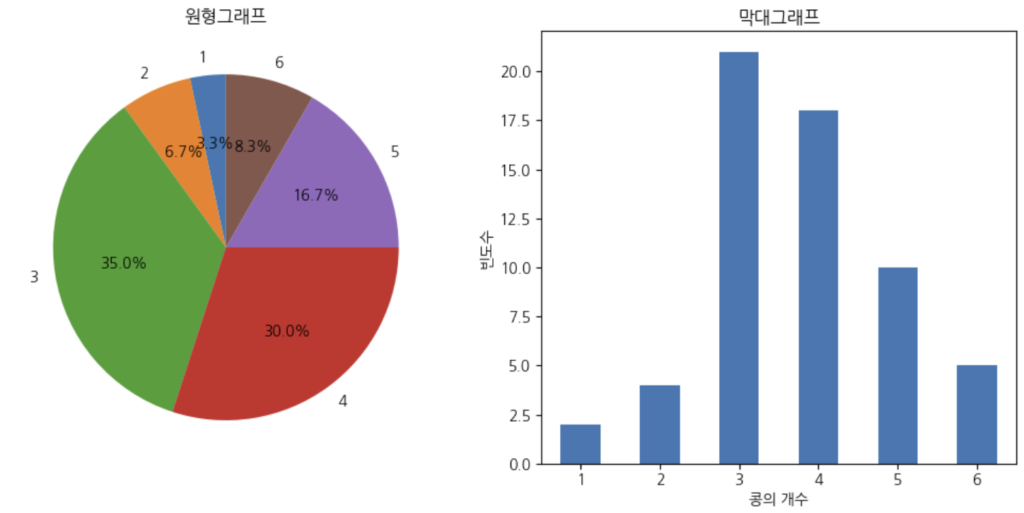
결론
오늘은 범주형 자료에서의 도수분포표, 원형그래프, 막대그래프, 파레토그림에 대해 colab에서 실습해보았습니다. 다음 포스팅엔 수치형 자료에서의 요약 형태를 다루어 보겠습니다.
참조
최신글
![[프로그래머스] 잘라서 배열로 저장하기 - 자바](https://develog.co.kr/wp-content/uploads/2025/01/프로그래머스-잘라서-배열로-저장하기-자바-150x150.png)
![[프로그래머스] 붕대 감기 - 자바](https://develog.co.kr/wp-content/uploads/2024/11/프로그래머스-붕대-감기-자바-150x150.png)
![[프로그래머스] 달리기 경주 - 자바](https://develog.co.kr/wp-content/uploads/2024/11/프로그래머스-달리기-경주-자바-150x150.png)